
Kubernetes wins over Apache Hadoop
A prediction of change in dominance between two siblings
Recently, Apache Hadoop 3 has been released. Really, who cares? Everyone and his aunt is jumping onto the Kubernetes train. While maybe it seems that Hadoop and Kubernetes are very different beasts, in reality, they are not. It’s kind of the same thing, but in different flavors. Yet, Kubernetes looks like the overall winner.
ℹ️ Update 2018-08-31: Added info box referencing Kubernetes history podcast and blog entry mid-article.
Slow clap: No more Hadoop talks on JAX 18
Something has changed. For the first time since 2009, I won’t be speaking at Europe’s biggest german-speaking IT-umbrella conference JAX in Mainz. During this time, I mostly held talks and workshops covering Hadoop (2009 through 2014). 2015 was a little different, I was glad to talk about the great Zookeeper, the most central and underestimated part of the Hadoop architecture. In the last two years, I covered more general topics: “Pitfalls of Distributed Systems” (2016) and “Hadoop vs Kubernetes in times of Cloud and Machine Learning”. While I think they delivered much more substantial content than my previous ones, they received good turn-out but only moderate feedback. (Thanks again for everyone who attended.) This year, I ran out of topics.
Nearly one year after the creation of my “Hadoop vs Kubernetes” slides, I’m finally blatantly recycling last year’s reasoning as a prediction for the new year 2018.
ℹ️ Update 2019-01-20: In early 2019 this prediction still holds, see also my Getting Started with Spark on Kubernetes post. However, now I will be talking again at JAX'19.
Hadoop on the Lonely Distributed Planet
Before Hadoop and Kubernetes, respectively, there were no large-scale distributed systems in the sense of the “warehouse-scale computer” easily available. There were large-scale network-attached storage-only systems (NAS) like AppNet or EMC: expensive and limited. There was HPC. Niches.
When the open source project Apache Hadoop emerged from 2006 onwards, we got two things:
- HDFS: an ultra-large distributed data store on commodity hardware
- YARN: a distributed fault-tolerance resource manager
The resource manager is assigning computing resources (CPU, RAM, sometimes even network bandwidth) to applications and their workers. Before Hadoop 2.0 resource management was handled by Hadoop’s MapReduce component.
Data and compute are colocated on the same machines, enabling data locality, a substantial performance gain over accessing data over the network.
While having some weak spots, Hadoop was the only system ready to lift substantial data loads in a distributed manner relatively easily. Adoption and contributions by BigData-processing organisations like Yahoo!, Twitter, Facebook, Apple and many more improved the scalability and richness of Hadoop. Quickly, a large ecosystem evolved (Hive, HBase and whatnot). Consequently, companies like Cloudera and Hortonworks formed as distributors, to help customers run Hadoop clusters and improve Hadoop itself a great deal.
Anybody out there?
Later, other players entered the distributed processing platform realm. Noteably Apache Mesos, which from early on used cgroups and LXC for worker isolation, but lacks the distributed file system, the same goes for Spark. None of these products was able to put a notable dent into the rise of the mainstream Hadoop platform. Only with the advent of Kubernetes, it seems imminent that there is a change. Why? Still, Kubernetes is completely different, isn’t it? While they both, Hadoop and Kubernetes, seem to be fruits, isn’t this comparing apples to oranges?
Origins, or: The Dark Side of the Moon
Let’s take a step back and quickly recap how Hadoop and Kubernetes came to be. Hadoop has been implemented at the Apache Software Foundation after two Google papers, GFS and MapReduce. It is the one and only open source implementation of them. But those papers were only a glimpse of what Google was building internally at that time in early 2000s.
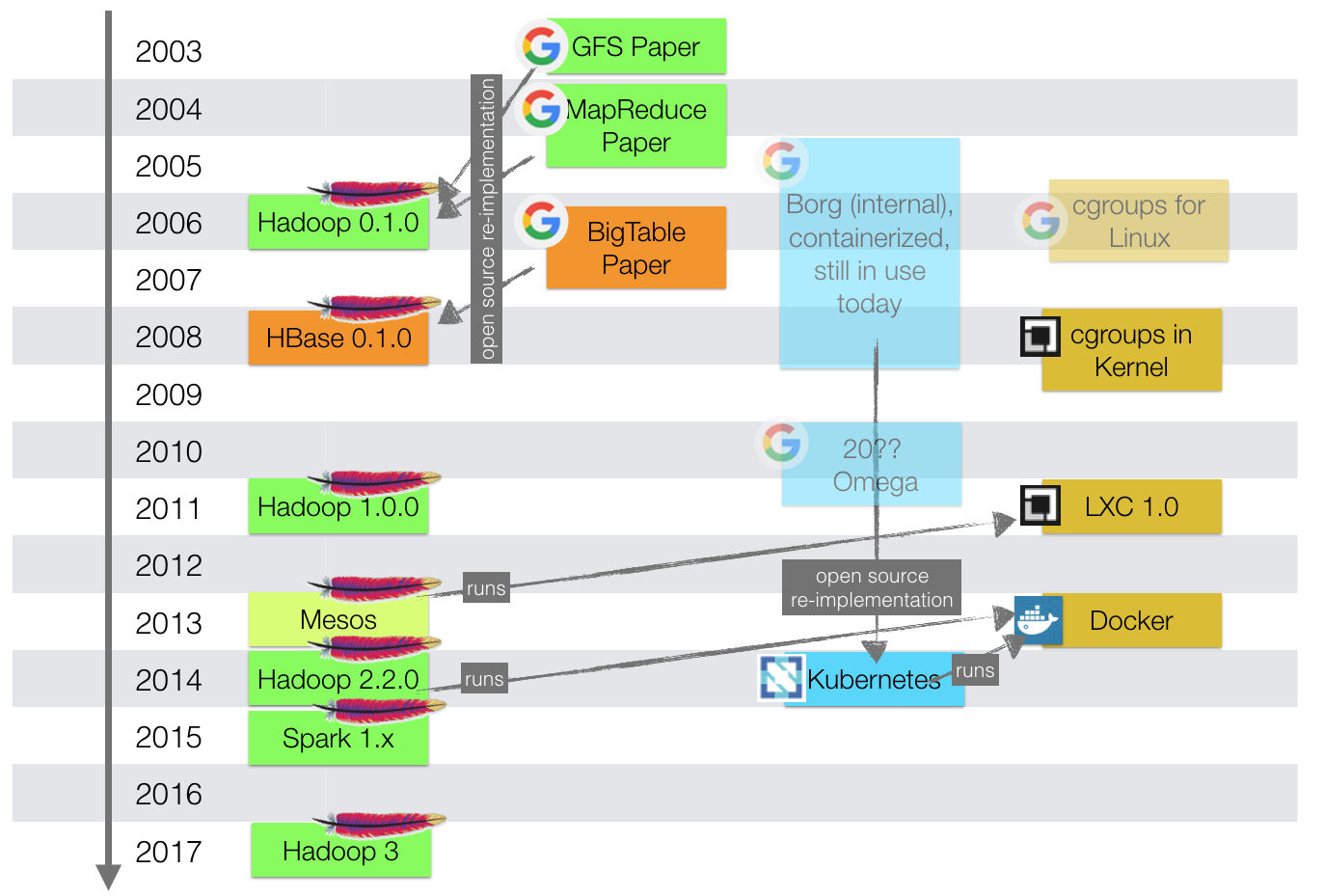
A big distributed platform had been created internally at Google, too. “Borg” was and still is their go-to resource management platform since 2005. Early on, Borg already used containers for isolation of distributed worker instances, roughly 10 years before Docker surfaced. GFS and MapReduce were running on Borg. So, in a way, roughly, Google’s equivalent of the publicly available
“Apache Hadoop“ = YARN + HDFS + MapReduce
was
“Hadoop@Google” _=_ Borg + GFS + MapReduce
In fact, Kubernetes is the third major (re-)implementation (see paper) of Borg produced by Google itself, now in the open under the CNCF umbrella.
Additionally, a short wrap up has been written down by Craig McLuckie on the official Google Cloud Platform Blog.
Fast Forward
Today, what is commonly called “Hadoop”, is actually more centered around Apache Spark than Hadoop itself. Yet, Hadoop is still a very important part of the platform equation, where Spark is running on YARN, making use of HDFS:
Hadoop = YARN + HDFS + Spark
While Borg still seems to be used at Google, GFS has evolved and MapReduce has been replaced.
Why should Kubernetes now become more successful than Hadoop?
Anticipate dragons: Retro-fitting security
In the beginning, Hadoop was basically a “trust all” system. Components and users were not required to authenticate at all. Authorization (file read/write access modelled after the Posix model) was using the client-side(!) user name and group affiliation which can easily be manipulated. It was assumed that Hadoop runs in an isolated environment. Sure enough, a number of openly accessible Hadoop clusters are exposed to the internet still today.
With Hadoop 2, intra-cluster security was retrofitted using Kerberos. It was painful and took quite some time. This work was still largely done by Yahoo! internally, before this group was spun out into what is today known as Hortonworks.
Apache Ranger and Apache Knox have been developed as separate projects from Apache Hadoop within the Apache Software Foundation. As far as Ranger and Knox are concerned the security aspects of the Hadoop ecosystem are not an integral part of the Hadoop core itself. Every “downstream” project now needs to look at what the Hadoop project changes on one side, and what those security projects change on the other side. It’s a mess.
(By the way, security is just one example. Search for “hadoop guava conflict” for another nice example of upstream/downstream conflict.)
The after effects of retrofitting security – which is generally a bad idea in the first place – can still be experienced today. Just ask your trusted Hadoop consultant, how to secure a Hadoop cluster within an existing company security landscape (hard) while integrating it securely with all the other components from the ecosystem like Spark, Hive, Kafka, HBase (very hard), and even third party vendor solutions (nearly impossible). And you did not deploy any applications yet!
Hadoop distributors will knit all this together into a nicely manageable distribution. However, the underlying setup with distinct projects will make evolution of security hard for this platform.
Kubernetes on the other hand has security built-in from the start. Every Kubernetes clusters uses it’s own root certficate authority and all workers (pods) are able to access the certificate. Intra-cluster communication is using HTTP/2, making TLS encryption mandatory. Kubernetes supports service accounts, role-bases security and effective plugging of different authentication methods. Everything seems well designed.
Scale Down
Whenever I hear that a “large” five node Hadoop cluster is in use, it makes me cringe. Especially if there are lot of add-ons from the Hadoop ecosystem in use. Such Hadoop deployments run lots of masters and agents. All (most) of them are JVMs. You can calculate the overhead. For small clusters this might be over 1/3 of all resources. Hadoop does not scale down very well. Thus, starting small with Hadoop is not really possible.
Kubernetes has agents on every node as well, but not one for every possible service! Currently there is only one master control plane, albeit consisting of multiple components, notably an etcd instance and the essential API server. If you are adding new functionality, instead of rolling out yet another layer of master plus agents on top of HDFS and YARN, you simply plug it into the control plane.
If you are running in a public cloud, for small Kubernetes clusters, the control plane might not even count against your own paid resources, but the cloud provider takes that on their hat. Anyway, the overhead is much smaller. And its trivial to expose web services securely.
Tiny Workloads
Hadoop comes from the BigData batch processing world. Every worker has at least reserved exclusively one CPU core or more. In Kubernetes, workers can be assigned fractions of a CPU, essentially sharing resources much more efficiently for small or often idling payloads. There is also more flexibility in defining CPU and RAM usage by specifying a reserved resource limit, which might then be exceeded up to a given maximum upper bound when the worker is finally disabled. For Hadoop this means that you need a lot more resources in the first place to process small and tiny workloads. But it also makes scheduling mixed workloads of all sizes (“bin packing“) in one cluster more difficult.
Spark on Kubernetes
Apache Spark is able to run standalone, on Hadoop, on Mesos. Soon, it will run native on Kubernetes as well. This will make it a very attractive alternative to Hadoop, enabling the move of existing Spark jobs off of Hadoop.
Kubernetes Disadvantages
In this article I’m not trying to do a fair comparison by looking into Hadoop’s advantages over Kubernetes in the same depth or emphasizing k8s weak spots. This is an opinionated text. Yet, not everything is wrong about Hadoop today that was true yesterday.
At least currently, Kubernetes is a resource management platform which is focused on transient applications, not so much a storage solution. HDFS might not be missed that much or it will be made available, or something like MINIO emerges. There is ongoing effort to run HDFS on Kubernetes.
But again here, in Kubernetes it’s as easy to add or remove any functionality as using any unix package manager (see Helm), while in the Hadoop world you need to wait for a major revision of your commercial Hadoop distribution.
Hypothesis: Hadoop market is shrinking
In addition to Hadoop’s scale-down issue, which limits its growths for any kind of problem, the Big Data market for on-premise Hadoop installations might be shrinking. I can’t prove it, but from my observation there are two strong arguments for that.
Suppose we define Hadoop’s market as the number of projects which need to process a certain amount of data, in the high terabyte to petabyte range and beyond:
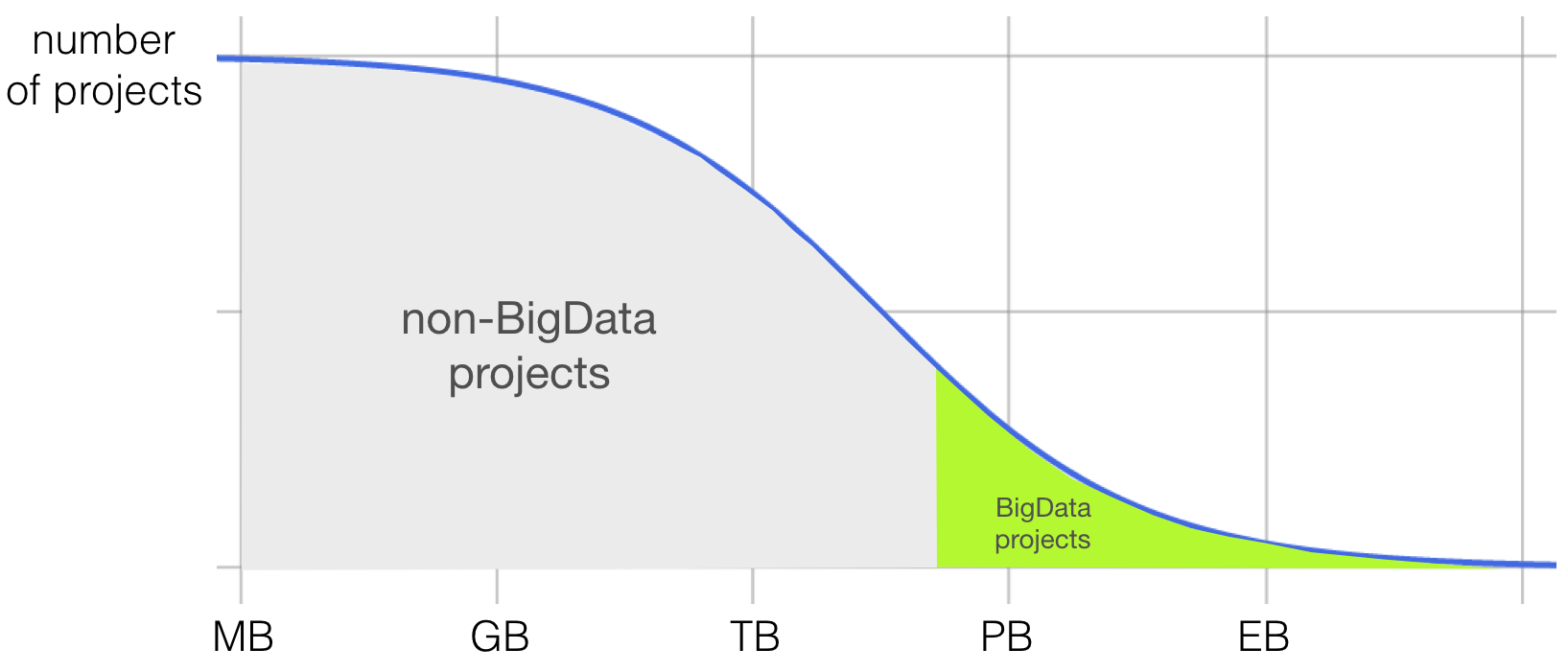
The more you move the slider to the right on the data size scale (horizontal axis), the less projects there are which are exposed to that amount of data. If you imagine that more projects are started which now handle much more data than previous projects would have, this whole wave moves to the right.
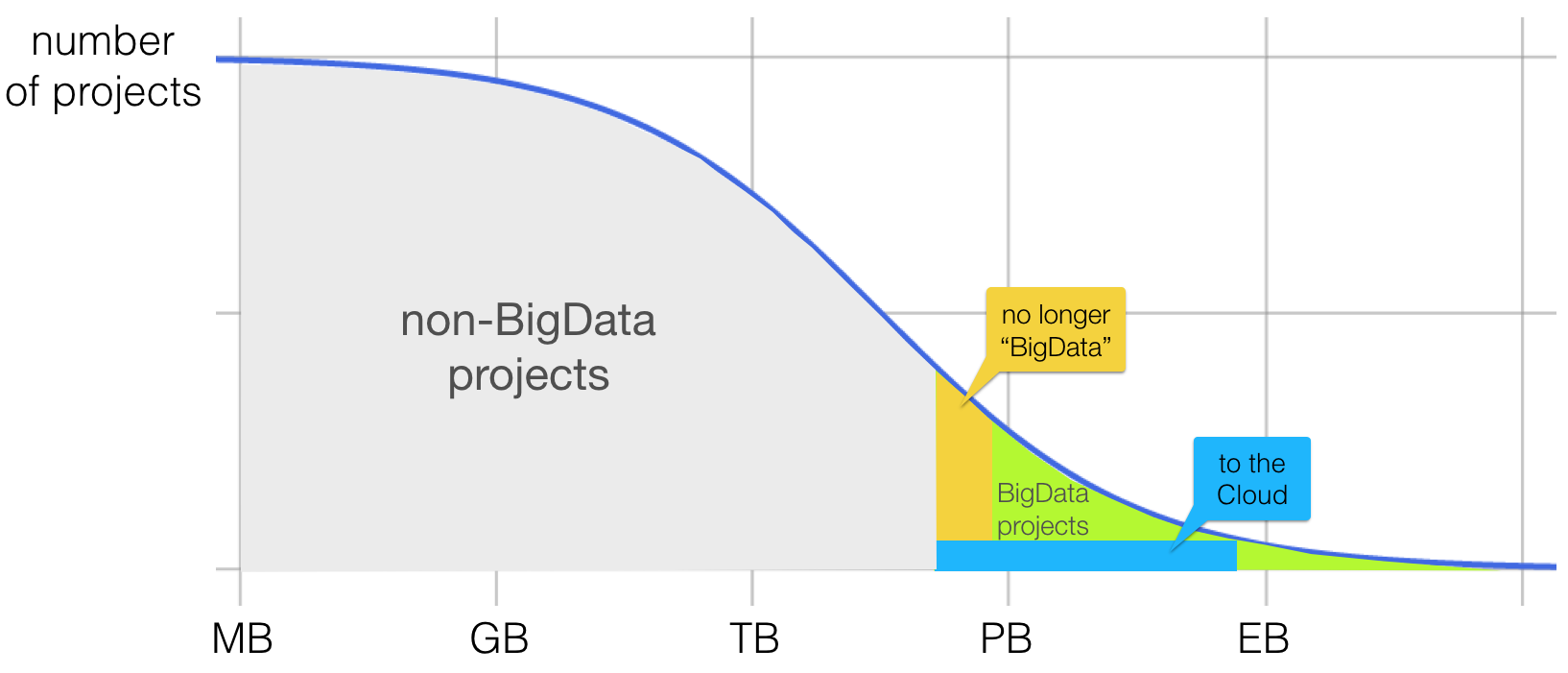
However, since computing power (CPU and RAM) is still growing in modern server systems, “classical” architectures become capable enough to eat into the left side of Hadoop’s cake.
Second, public clouds put a lot of effort into providing Big-Data-capable setups. Not only by supporting managed Hadoop in the cloud, but also by providing non-Hadoop hosted products like Sharded SQL Servers, or going far beyond Hadoop’s capabilities with world-wide fully-managed OLAP databases (Cloud Spanner or Azure Cosmos), in addition to beasts like AWS S3. Public Clouds fully embrace Big Data (AWS, Azure, GCP).
Kubernetes unleashed
The market for Kubernetes seems less restricted, at least for now:
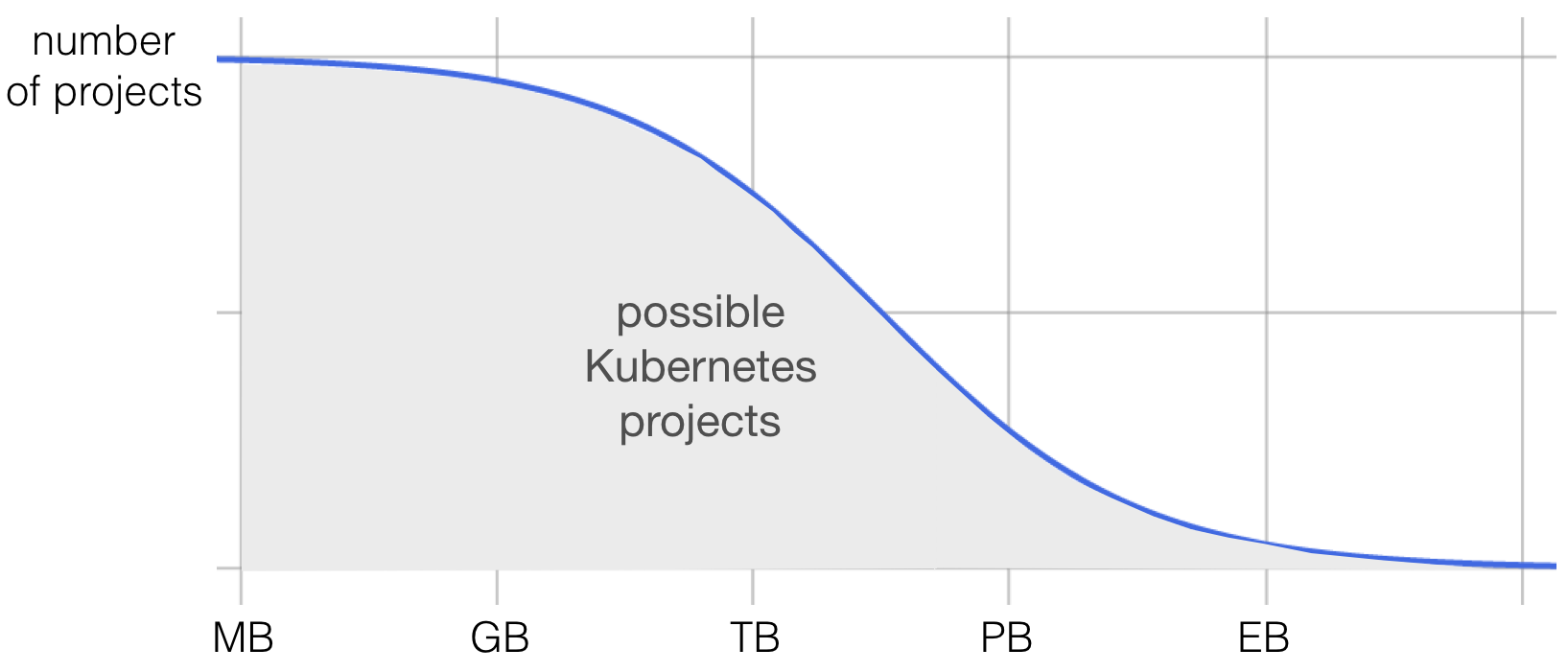
All major cloud providers currently adopt more or less native Kubernetes offerings. Azure puts managed Kubernetes before their own container service, AWS adds Kubernetes as a first class citizen (EKS), while Google always put their bets on Kubernetes.
As far as JAX 2018 goes, there are zero talks carrying “Hadoop” in the title this year although Hadoop 3.0 has recently been released , one with “Spark” (not enough), but surprisingly only two with “Kubernetes”. (Yet four with “Serverless”, none for the Go language.) Something has changed. It’s an interesting observation that my perception of the field is not in line with what is discussed on a mainstream conference. – Anyway, where’s my helm?
2018-01-18: Updated with corrections and input from Lars Francke and the rest of the great OpenCore community.